This article looks at optimising a Java Spring Boot application (Cloud Function style) with AWS SnapStart, and covered advanced optimisation with lifecycle management of pre snapshots and post restore of the application image by AWS SnapStart. We cover optimising a lambda for persistent network connection style conversational resources, such as an RDBMS, SQL, legacy messaging framework, etc.
How Snap Start Works
To import start up times for a cold start, SnapStart snapshots a virtual machine and uses the restore of the snapshot rather than the whole JVM + library startup time. For Java applications built on frameworks such as Spring Boot, this provides order of magnitude time reductions on cold start time. For a comparison with raw, SnapStart and Graal Native performance see our article here.
What frameworks do we use with Spring Boot?
For our Java Lambdas we use Spring Cloud Function with the AWS Lambda Adaptor. For an example for how we set this up, and links to our development frameworks and code, see our article AWS SnapStart for Faster Java Lambdas
Default SnapStart: Simple Optimisation of the Lambda INIT phase
When the lambda version is published SnapStart will run up the Java application to the point that the lambda is initialised. For a spring cloud function application, this will complete the Spring Boot lifecycle to the Container Started phase. In short, all your beans will be constructed, injected and started from a Spring Container perspective.

SnapStart will then snapshot the virtual machine with all the loaded information. When the image is restored, the exact memory layout of all classes and data in the JVM is restored. Thus any data loaded in this phase as part of a Spring Bean Constructor, @PostCreate annotated methods and ContextRefresh event handlers will have been reloaded as part of the restore.
Issues with persistent network connections
Where this breaks down is if you wish to use a “persistent” network connection style resource, such as a RDBMS connection. In this example, usually in a Spring Boot application a Data Source is configured and the network connections initialised pre container start. This can cause significant slow downs when restoring an image, perhaps weeks after its creation, as all the network connections will be broken.
For a self healing data source, when a connection is requested the connection will check, timeout and have to reconnect the connection and potentially start a new transaction for the number of configured connections in the pool. Even if you smartly set the pool size to one, given the single threaded lambda execution model, that connection timeout and reconnect may take significant time depending on network and database settings.
Advanced Java SnapStart: CRaC Lifecycle Management
Project CRaC, Co-ordinated Restore at Checkpoint, is a JVM project that allows responses to the host operating system having a checkpoint pre a snapshot operation, and the signal that a operating system restore has occurred. The AWS Java Runtime supports integration with CRaC so that you can optimise your cold starts even under SnapStart.
At the time of our integration, we used the CRaC library to create a base class that could be used to create a support class that can handle “manual” tailoring of preSnapshot and postRestore events. Newer versions of boot are integrating CRaC support – see here for details.
We have created a base class, SnapStartOptimizer, that can be used to create a spring bean that can respond to preSnapshot and postRestore events. This gives us two hooks into the lifecycle:
- Load more data into memory before the snapshot occurs.
- Restore data and connections after we are running again.
Optimising pre snapshot
In this example we have a simple Spring Component that we use to exercise some functionality (http based) to load and lazy classes, data, etc. We also exercise the lookup of our spring cloud function definition bean.
@Component
@RequiredArgsConstructor
public class SnapStartOptimisation extends SnapStartOptimizer {
private final UserManager userManager;
private final TradingAccountManager accountManager;
private final TransactionManager transactionManager;
@Override
protected void performBeforeCheckpoint() {
swallowError(() -> userManager.fetchUser("thisisnotatoken"));
swallowError(() -> accountManager.accountsFor(new TradingUser("bob", "sub")));
final int previous = 30;
final int pageSize = 10;
swallowError(() -> transactionManager.query("435345345",
Instant.now().minusSeconds(previous),
Instant.now(),
PaginatedRequest.of(pageSize)));
checkSpringCloudFunctionDefinitionBean();
}
}Optimising post restore – LambdaSqlConnection class.
In this example we highlight our LambdaSqlConnection class, which is already optimised for SnapStart. This class exercises a delegated java.sql.Connection instance preSnapshot to confirm connectivity, but replaces the connection on postRestore. This class is used to implement a bean of type java.sql.Connection, allowing you to write raw JDBC in lambdas using a single RDBMS connection for the lambda instance.
Note: Do not use default Spring Boot JDBC templates, JPA, Hibernate, etc in lambdas. The overhead of the default multi connection pools, etc is inappropriate for lambda use. For heavy batch processing a “Run Task” ECS image is more appropriate, and does not have 15 minute timeout constraints.
So how does it work?
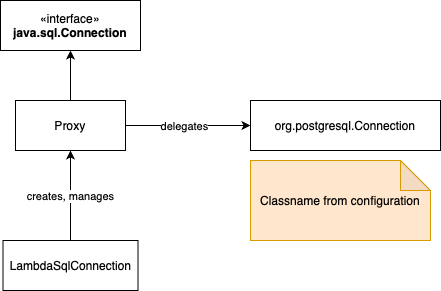
- The LambdaSqlConnection class manages the Connection bean instance.
- When preSnapshot occurs, LambdaSqlConnection closes the Connection instance.
- When postRestore occurs, LambdaSqlConnection reconnects the Connection instance.
Because LambdaSqlConnection creating a dynamic proxy as the Connection instance, it can manage the delegated connection “behind” the proxy without your injected Connection instance changing.
Using Our SQL Connection replacement in Spring Boot
See the code at https://github.com/LimeMojito/oss-maven-standards/tree/master/utilities/aws-utilities/lambda-sql.
Maven dependency:
<dependency> <groupId>com.limemojito.oss.standards.aws</groupId> <artifactId>lambda-sql</artifactId> <version>15.0.2</version> </dependency>
Importing our java.sql.Connection interceptor
@Import(LambdaSqlConnection.class)
@SpringBootApplication
public class MySpringBootApplication {You can now remove any code that is creating a java.sql.Connection and simply use a standard java.sql.Connection instance injected as a dependency in your code. This configuration creates a java.sql.Connection compatible bean that is optimised with SnapStart and delegates to a real SQL connection.
Configuring your (real) DB connection
Example with Postgres driver.
lime:
jdbc:
driver:
classname: org.postgresql.Driver
url: 'jdbc:postgresql://localhost:5432/postgres'
username: postgres
password: postgresExample spring bean using SQL
@Service
@RequiredArgsConstructor
public class MyService {
private final Connection connection;
@SneakyThrows
public int fetchCount() {
try(Statement statement = connection.createStatement()){
try(ResultSet results = statement.executeQuery("count(1) from some_table")) {
results.next();
results.getInt(1);
}
}
}
}References
- AWS SnapStart: https://docs.aws.amazon.com/lambda/latest/dg/snapstart.html
- Cold Start Timings: https://limemojito.com/native-java-aws-lambda-with-graal-vm/
- Using AWS Snapstart for Faster Java Lambdas: https://limemojito.com/aws-snap-start-for-faster-java-lambda/
- Project CRaC: https://github.com/CRaC/docs
- Spring Framework CRaC integration: https://docs.spring.io/spring-framework/reference/integration/checkpoint-restore.html