We have a web service responding to web requests. The service has a thread pool where each web request uses one operating system thread. The requests are then managed by a multi-core CPU that time-slices between the various threads using the operating system scheduler.
This example is very similar to how Tomcat (Spring Boot MVC) works out of the box when servicing requests with servlets in the Java web server space. The Java VM (v17) matches a Java Thread to an operating system thread that is then scheduled for execution by a core.
So what happens when we have a lot of requests?

Many threads here are sliced between the 4 cores. This slicing of threads where a core works on one for a while, then context switches to another thread, can scale to any level. However, there is an expense in CPU time to switch between one thread to another. This context switch is expensive as it involves both memory and CPU manipulation.
Given enough threads, the CPU cores can quickly spend a significant amount of time context switching when compared to the actual amount of time processing the request.
How do we reduce context switching?
We can trade off context switching for latency by blocking a request thread until a vCPU is available to do the work. Provided the work is largely CPU bound this may reduce the overall throughput time if the context switching has become a major use of the available vCPU resources.
For our Java spring boot based application we introduce one of the standard Executors to provide a blocking task service. We use a WorkStealingPool which is an executor that defaults the worker threads to the number of CPUs available with an unlimited queue depth.
We now move the CPU heavy process into a task that can be scheduled onto the executor by a given thread. The thread will then block on the Future returned from submitting the task – this blocking occurs until a worker thread has completed the task’s job and returned a result.
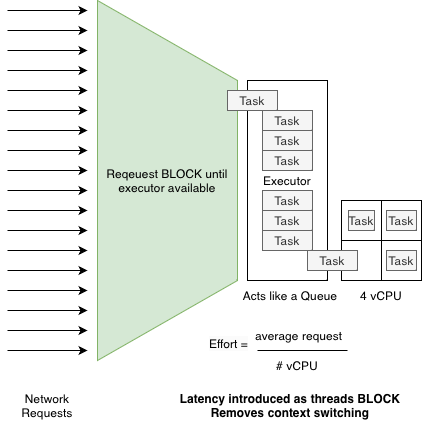
On our application, this returned a 5X improvement to average throughput times for the same work being submitted to a single microservice performing the request processing. This goes to show that in our situation the majority of CPU was being spent on context switching between requests rather than servicing the CPU intensive task for each request.
In our case this translated to 5X less CPU required and a similar reduction in our AWS EC2 costs for this service as we needed less instances provisioned to support the same load.